The Long Accommodation
How UX research traded disciplinary authority for organizational fit

UX research gave something up. The field traded disciplinary authority for organizational fit, and it did so gradually enough that no single decision looks like the culprit.
The more comfortable version of this story blames organizations: product teams moved too fast, PMs didn’t understand research, leadership kept the function in a service role when it deserved more. That version isn’t wrong, but it’s incomplete.
At the center of what research does, or should do, are two things. Validity: whether the evidence actually supports the claim being made. Decision relevance: whether the research is answering the question the organization actually faces. Validity requires methodological grounding, sampling discipline, and interpretive honesty. Decision relevance requires knowing what decision is live, what would change it, and whether the study being proposed is actually built to answer it.
Everything else in research, the methods, the deliverables, the presentations, the stakeholder relationships, exists in service of those two things. A finding that is valid but answers the wrong question doesn’t help anyone make a better decision. A finding that answers the right question but isn’t supported by adequate evidence doesn’t hold when it’s tested. A discipline built around these two spines would have been hard to dismiss, because it would have been doing something irreducibly difficult that required genuine expertise.
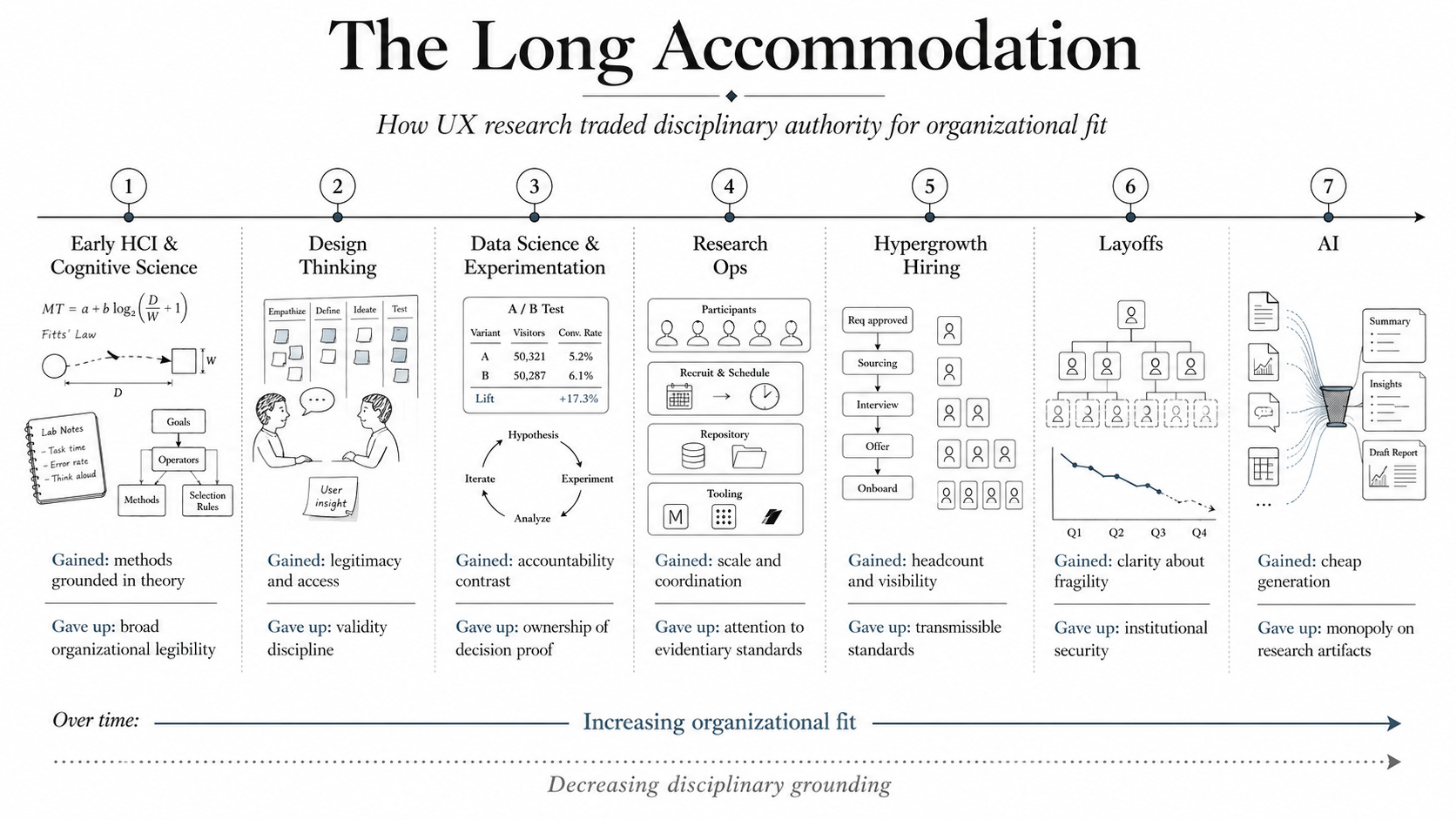
That discipline didn’t get built. At several moments when the field could have consolidated around validity and decision relevance as its core, it chose accommodation instead, not out of weakness or failure of character, but as a rational response to real pressures: fitting in, staying useful, keeping the work coming. Each choice made sense in the moment it was made. The cumulative effect was a field organized around vague influence impressions and volume rather than around the two things that made it worth having in the first place.
Getting honest about how we arrived here means going back to those moments and being clear about what they required and what we chose instead.
The methods survived the translation. Validity didn’t come with them.
Academic HCI in the 1980s and early 1990s was doing serious work. Fitts’ Law, mental models, cognitive load theory, Card, Moran, and Newell building predictive models of human-computer interaction grounded in cognitive science. When practitioners from that world moved into industry, through Bell Labs, Xerox PARC, early Microsoft, they brought methods with them: card sorting, think-aloud protocols, heuristic evaluation.
What didn’t make the translation was the epistemological substrate underneath those methods. In the academic context, a think-aloud was a window into cognitive processing, interpreted against a theoretical framework that gave the interpretation its validity. In a product context, it became a way to watch someone use a prototype and note where they got confused. Useful, but different. The method survived the crossing; the reasoning that made the method’s conclusions valid didn’t.
The accommodation was understandable. Industry moved fast and wanted tools, not theory, and researchers who led with cognitive science frameworks found less traction than researchers who showed up with a protocol and a report. The translation stripped the validity infrastructure because it was harder to carry and no one was requiring it at the destination.
The consequence was that methods became techniques. Detached from their validity grounding, they could be borrowed, diluted, and misapplied without anyone having a principled basis for objecting, which meant a think-aloud with five participants could be made to prove whatever the team wanted it to prove. Decision relevance was rarely discussed at all. That’s exactly what played out over the following decades.
Design thinking offered legitimacy, and research took the trade
The moment that did the most lasting damage came in the mid-2000s with the mainstreaming of design thinking. The d.school’s curriculum took a process IDEO had been running for years and made it teachable, scalable, and legible to business leadership, giving organizations a framework for innovation that foregrounded user empathy and that any team could run a workshop on.
The vocabulary sounded like research: empathy interviews, insights, user needs. But design thinking had removed both validity and decision relevance as requirements. An insight was an observation that felt generative; an empathy interview was a conversation that built understanding. Whether the interpretation was defensible, whether the sample was adequate for the inference, whether the output would actually inform a decision, none of those questions had to be asked. The feeling of understanding users was enough.
Research had the standing to draw a line here, to say plainly that observation without analytical framework and sampling logic does not produce valid evidence, and that generative feeling is not the same as decision relevance. It didn’t.
Design thinking was winning organizational legitimacy at exactly the moment when research was still struggling to establish its own, and proximity to that legitimacy was worth something. Researchers who could speak design thinking language got more access; teams that could run a sprint got invited into processes that research teams weren’t.
The accommodation made sense individually and in the short term. Collectively it cost the field its definitional core. Once you accept that an empathy interview and a depth interview analyzed against a theoretical frame are producing evidence on the same epistemic footing, you lose any principled basis for saying a particular study was done poorly. Validity and decision relevance became optional features rather than the organizing logic of the work, the floor dropped, and there was no agreed standard left to appeal to.
Data science built credibility through experimentation. Research had no equivalent feedback loop.
In the early 2010s, data science had a similar identity problem. The term covered statisticians, machine learning engineers, SQL analysts, and people who made charts in Excel, and for a while it looked like it might stay as elastic as research had become.
What consolidated it was experimentation as infrastructure. A/B testing at scale, causal inference frameworks, the ability to connect analytical work directly to product outcomes: data science built indispensability by owning the mechanism that linked decisions to results. An experiment either moved the metric or it didn’t, and that feedback loop was structural and short. You could be wrong in a way that was visible and consequential, and that visibility forced the standards up.
This is, more than anything else, a story about decision relevance. Data science earned its position by being directly accountable to decisions and their outcomes, and it couldn’t hide behind influence because the experiment either worked or it didn’t. That accountability raised validity standards too, because an analysis with selection bias produced a wrong answer that eventually showed up in the data.
Research owned the front of the process, understanding users, surfacing problems, framing what to build, but it had no equivalent mechanism for closing the loop. Whether a finding was valid, whether it was actually decision-relevant, only became visible if someone went back to check, and the organizational incentives for doing that were weak. A study that shaped a product direction that later failed was almost never traced back to the research. The accountability stopped at the presentation, and because it stopped there, no structural pressure accumulated to build validity or decision relevance into the work more carefully. The accommodations made over the prior decades could persist invisibly, because there was never a moment when they became costly enough to force a reckoning.
Academic imports brought rigour, but calibrated for the wrong problem
At the same time that design thinking was flattening the floor, researchers with academic training were moving into industry and adding a different complication.
Rigor in academic social science means controlling for confounds, representative sampling, reproducibility across contexts, theoretical grounding: real standards that produce real knowledge, but calibrated for a specific problem, which is contributing to a cumulative body of evidence that generalizes beyond any single context. Industry research has a different obligation. It has to reduce uncertainty enough for a team to make a better decision under real constraints: limited time, partial evidence, shifting product context, and decisions that won’t wait for a cleaner study. A valid industry finding isn’t one that would survive peer review. It’s one that was adequate for the decision it was meant to inform.
That distinction was never worked out. When academic rigor moved into industry, it brought the apparatus without the translation. Studies got more methodologically elaborate, sampling criteria got tighter, analysis got more systematic, but the question of whether any of it was reducing the right uncertainty for the decision actually in front of the team often went unasked. The validity machinery ran, but it was pointed at reproducibility when the real question was whether this team should build this thing.
The accommodation ran in both directions. Academic researchers softened their standards where it was inconvenient and tightened them where it signaled credibility; practitioners deferred to academic framing because it sounded authoritative. Neither group did the harder work of defining what validity and decision relevance actually require in an industry context, across different types of claims, different timelines, different decision stakes. The result was a field with two competing intuitions about what good work meant, no mechanism for resolving the tension, and a default that collapsed to whatever was rigorous-looking enough to be credible and fast enough to ship.
Research ops scaled the volume. Validity and decision relevance didn’t make the agenda.
By the late 2010s, organizational scale made the infrastructure question unavoidable, and research operations emerged as a function: conferences, tooling, participant panels, dedicated coordinators. It looked like the moment to build the scaffolding a discipline needs, shared frameworks for what counts as valid evidence, norms around study design and decision relevance, some way of accumulating organizational knowledge about what research had found and whether its claims held up.
What research ops mostly became was logistics, and the reason has less to do with ambition than with organizational legibility. Recruitment coordination, consent forms, tool procurement are problems with clear owners, measurable outputs, and no contested ground. Whether a study design was valid for the claims being made from it required methodological judgment that ops practitioners often didn’t have, created friction with researchers who wanted their work endorsed rather than interrogated, and produced no artifact that a stakeholder could point to. Validity infrastructure is slow to build, hard to demonstrate, and easy to defer when there are concrete problems waiting to be solved.
So the organizational energy went into scaling volume. More studies, faster, better coordinated, with less friction. The community built what it could build without conflict and deferred the rest. The two things that mattered most were the two things that were hardest to systematize, so they got left out, not because no one saw the gap, but because closing it would have required ops to position itself against researchers rather than in service of them.
Hypergrowth hired at scale and made the underlying emptiness visible
Then came the Covid growth years, and the structural weaknesses that had been accumulating got stress-tested at a scale they hadn’t seen before.
Between 2020 and 2022, companies hired research teams at a pace the pipeline couldn’t support, with the number of UX researchers at large tech companies roughly doubling in some cases. The people moving into those roles came from bootcamps, adjacent functions, and academic programs that hadn’t prepared them for the specific demands of industry practice, and hiring managers who didn’t themselves have deep research backgrounds were evaluating candidates against proxies: communication skills, portfolio presentation, familiarity with tools. Surface fluency looks the same as epistemological grounding in a portfolio. The field had never built the shared standards that would have made the difference visible, so the difference didn’t get evaluated.
The result was a large cohort of practitioners who had the vocabulary of research without the foundation underneath it, not through individual failure, but because there was nothing transmissible to pass on. When you scale hiring inside a field that hasn’t codified what good work actually requires, you replicate whatever was legible, and what was legible was the surface.
The contraction that followed made this visible in the hardest way. Research was cut disproportionately in the 2022 and 2023 layoff cycles, and when the question became what research produces that a PM running a survey or a designer doing user interviews can’t replicate, many organizations didn’t have a clear answer. Functions with clear output expectations are harder to dismiss because the organization can see what it’s losing. Research had underinvested in validity and decision relevance long enough that its absence was genuinely hard to distinguish from its presence.
The language of influence removed the pressure to build what actually mattered
Running through all of this is a structural dynamic that shaped what research could realistically be held to. In most organizations, research success was defined as influencing decisions, changing minds, having impact.
The language was deliberately soft, and the softness was itself an accommodation: to organizations that hadn’t committed to what research was for, to stakeholders who wanted findings to support existing directions, to a function still making the case for its own existence.
Influence as a success criterion meant research got evaluated on persuasion rather than on whether its evidence held or whether it answered the right question. There was no mechanism for tracing a decision back to the research that informed it, no consequence when research that was acted on turned out to be invalid. The accountability stopped at the presentation, and because it stopped there, the vague expectations that filled the gap weren’t just a symptom of organizational immaturity. They were, over time, a structural condition that made building around validity and decision relevance harder than leaving things as they were.
Design fought for its definition. Research deferred the fight.
Design had a parallel identity crisis and resolved it differently. The question of whether design was decoration or strategy was fought out publicly and messily across the 2000s and 2010s. Design systems gave designers something concrete to own that required real expertise; strategic design gave senior practitioners language for organizational influence that wasn’t just aesthetics. The fight had costs and not everyone won, but the field came out of it with more definition than it went in with.
Research largely avoided that fight, and the avoidance was itself a form of accommodation. Methodological pluralism was the justification: all approaches have value, context determines appropriateness, drawing hierarchies excludes practitioners who work differently. These are legitimate concerns that also, when applied to every methodological dispute, function as a way of preventing the field from ever committing to what validity and decision relevance actually require. Design accepted that consolidation would mean some framings losing. Research kept deferring that cost, and the deferral accumulated.
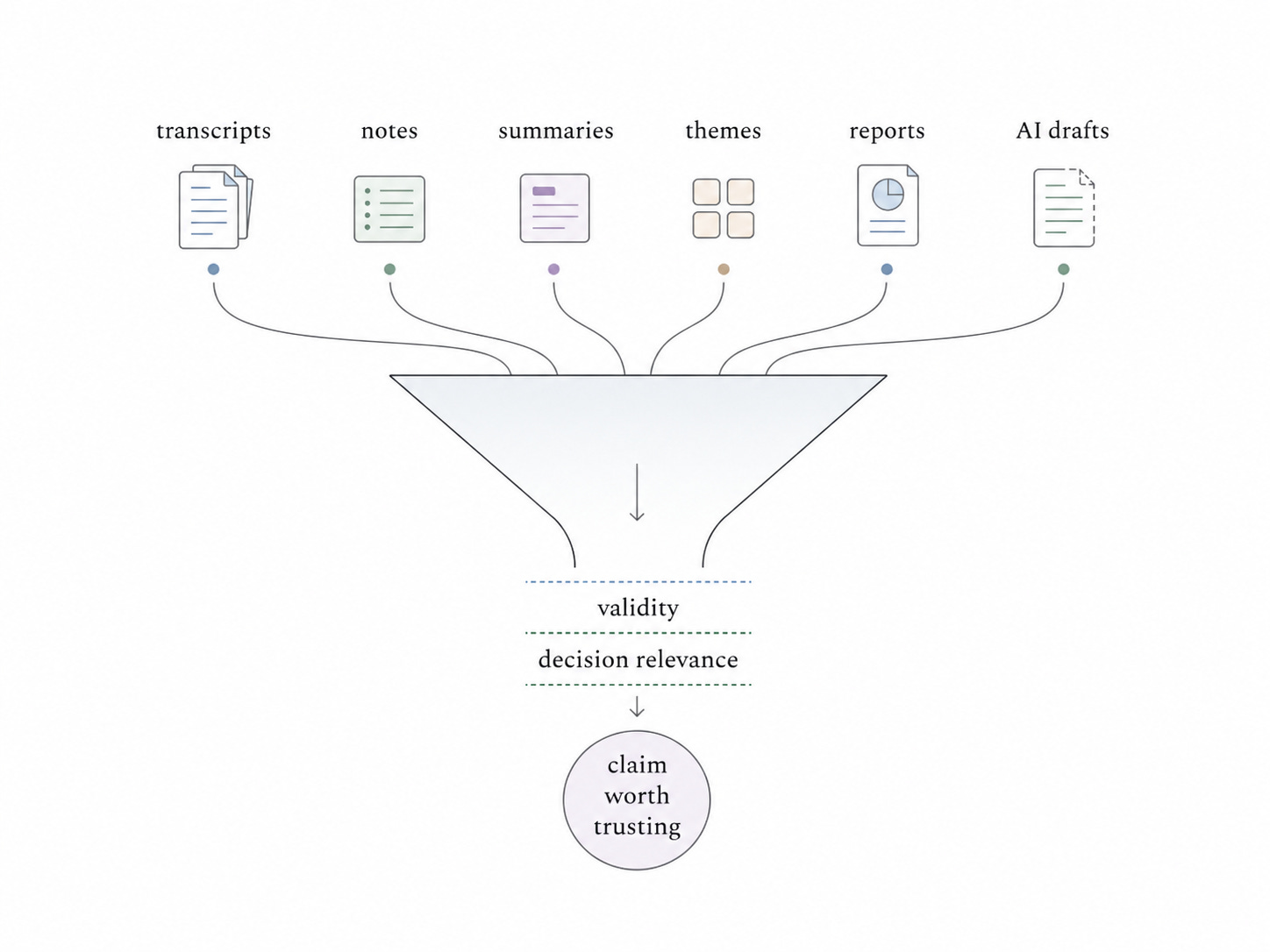
AI is making generation cheap. Validity and decision relevance are the bottleneck.
The arrival of AI in research workflows is often framed as a threat. It shouldn’t be, but the reframing requires being honest about what AI actually changes and what it doesn’t.
Generation is getting cheap. Recruiting participants, running sessions, transcribing interviews, synthesizing themes, producing reports: these are increasingly automatable, and the cost of producing research artifacts is falling fast. A PM who wanted research but couldn’t get researcher time now has tools. This is exactly where the long accommodation becomes a liability rather than a sustainable position.
What AI makes cheap is research organized around volume and influence: synthesizing interview themes, surfacing patterns in open-ended responses, drafting findings reports that sound like research. Whether that changes is an open question. What doesn’t change is what the work is actually for.
Validity and decision relevance are not generation problems. They are accountability problems. Someone has to be responsible for whether the evidence supports the claim, whether the study was designed to answer the decision actually in front of the team, whether a finding is being stretched beyond what the data can carry. That accountability doesn’t dissolve when generation gets cheaper. If anything, cheaper generation makes it more load-bearing, because the volume of research artifacts that need to be evaluated goes up while the signal-to-noise ratio doesn’t automatically improve.
That is where research has something specific to build around: not a claim about what AI can or cannot do, but a clearer definition of what researchers are accountable for. The question of whether a claim is supported, whether it answers the right question, whether it should be trusted enough to act on. That is the work the accommodation consistently deferred. It’s also the work that remains when everything else gets automated.
The long accommodation was a rational response to real pressures across several decades. But the conditions that made it sustainable are gone. What that opens up, for the first time in a while, is a clearer argument for what research is actually for. Not influence, not volume, not proximity to decisions, but the thing that was always underneath those proxies: evidence worth trusting, pointed at questions that matter. AI makes the routine parts faster. It makes the case for that discipline easier to see.
Thank you for this! I wonder, if AI can help us build this level of accountability by more transparently connecting the insights that were produced and the organizational outcomes. Given how some organizations are building “second brains”, seeing the relationships between research outcomes and analytics experiments outcomes might become easier.
This is very convincing, and gives us something clear and urgent to organize around (accountability), should we choose to. Thank you for this post.
An ops example: It brings my mind to the difficulty of structuring UX research insights consistently, across studies and teams, for the container of an “insights repository.” Decision relevance has been enforced plenty, at many places I worked. I'm lucky for that experience, but together with the push for speed, studies meant to produce evergreen, foundational knowledge were often discussed and rarely commissioned.
So, if a repository is filled with insights from studies focused on decisions for a range of time horizons (but mostly short), with a range of rigor, and includes insights from democratized studies from non-research practitioners....What a challenge to structure the inputs for quality outputs and to give the subsequent users of those insights a realistic picture of their relevance and validity re: the new research question. The accommodation I've seen, as a result, was simplifying that challenge to some other, more manageable design problem. Tags, for example.
AI-assisted search of an organization's research repository can make a repository search *seem* more usable and fruitful. Can it make it more feasible for researchers to structure their insight and frame for others how they do and don't apply to new questions? It seems like one place we could think through the specifics of what accountability would look like.