Different Sampling Methods for Survey Research
Pros and cons and when to use them

In my previous post, I wrote about the broad set of skills and knowledge areas worth developing as a quantitative researcher. For this and future posts, I’ll go deeper into specific topics. Today, I’ll focus on survey sampling methods—the backbone of credible research.
Choosing how you sample determines whether your findings are reliable, biased, or even usable. Below, I’ll walk through the most common sampling methods, their pros and cons, and when you might use each one, with practical examples to make it concrete.
Random Sampling
Random sampling gives every population member an equal chance of selection, making it the gold standard for eliminating bias and ensuring statistical validity. It's ideal when you have a complete sampling frame and want straightforward, generalizable results. The trade-off is potential underrepresentation of small subgroups and higher costs, but it provides the strongest foundation for statistical inference and generalizable results.
Pros:
Eliminates Selection Bias: Each member of the population has an equal chance of being selected, which helps in obtaining a representative sample. No human judgement or systematic factors influence who gets chosen.
Simplicity: Easy to understand and implement.
Statistical Validity and Generalizable Results: Facilitates the use of inferential statistics and confidence intervals to generalize results to the broader population.
Cons:
Resource-Intensive: Can be time-consuming and costly, especially for large populations.
May Miss Important Sub-Groups - Small or rare populations might not be represented by chance or may not have enough members from specific groups to analyze separately.
Need the Complete Sampling Frame: Requires a comprehensive list of the population, which might not always be available.
Potential Bias with Hidden Systematic Patterns - Your sampling frame might have an underlying organization you're not aware of. For example: Student ID numbers might be assigned by enrollment date or program
Example: You want to survey 200 students at a university with 10,000 total students about campus dining satisfaction. With random sampling, you'd:
Get a complete list of all 10,000 students
Use a random number generator to select 200 student ID numbers
Survey those 200 students
This might give you 150 undergraduates, 45 graduate students, and 5 doctoral students - roughly reflecting the university's composition. However, you might randomly get very few freshmen or accidentally oversample engineering majors, simply due to chance.
Stratified Sampling
Stratified sampling divides a population into distinct subgroups (strata) based on important characteristics, then samples from each stratum. This ensures representation from all key segments of your population. It's perfect when you need to analyze specific subgroups or ensure minority populations aren't missed, commonly used in demographic studies, market segmentation research, and policy evaluation. The trade-off is increased complexity and planning requirements for significantly improved precision and subgroup analysis capabilities.
Pros:
Increased Precision: By dividing the population into subgroups (strata) and sampling from each, it ensures representation across key variables, leading to more precise estimates.
Better Representation for Specific Groups: Guarantees all important subgroups are included, even small ones that might be missed in simple random sampling
Better Comparisons: Allows for detailed comparisons between strata.
Reduces sampling bias: Prevents over-representation of easily accessible groups
Cons:
More Complex and Expensive: More complicated to organize and analyze compared to random sampling. Managing separate sampling frames for each stratum adds logistical complexity.
Requires Prior Knowledge: Needs detailed information about the population to form appropriate strata.
Potential for poor stratification - If strata aren't well-chosen or homogeneous within groups, benefits diminish
Example: You want to survey 1,000 employees at a large company about job satisfaction. The company has 60% office workers, 30% factory workers, and 10% management. With stratified sampling, you'd sample:
600 office workers
300 factory workers
100 managers
This ensures all three groups are proportionally represented. Without stratification, random sampling might accidentally select mostly office workers (since they're the largest group), giving you little insight into factory worker or management perspectives. The key is choosing strata that are internally similar but different from each other depending on the characteristic you're studying.
Systemic Sampling
Systematic sampling selects every nth member from a population list after randomly choosing a starting point. For example, if you need 100 people from a list of 1,000, you'd select every 10th person after randomly picking where to start. It's most practical for quality control, manufacturing inspection, and operational surveys where workflow efficiency matters, such as testing every 100th product or surveying every 50th customer. The trade-off is vulnerability to hidden periodic patterns in the list for much simpler implementation and better geographic or temporal distribution than pure random sampling.
Pros:
Simplicity: Easier to implement than random sampling if you have a list of the population.
More Evenly Distributed and Good Coverage- Spreads selections across the entire population list, avoiding clustering. Ensures representation from beginning, middle, and end of your sampling frame
Cons:
Risk of Periodicity: If the list has a hidden periodic pattern, it can bias the sample.
Not Truly Random - Once you pick the starting point and interval, all other selections are predetermined
Requires Ordering: Needs the population to be ordered, which might not always be straightforward.
Can't Calculate Sampling Error Properly - Standard statistical formulas assume true random sampling.
Risk of Systematic Bias - If list ordering relates to your research topic, results may be skewed
Example: You want to survey 200 customers from a database of 10,000. Your sampling interval is 10,000 ÷ 200 = 50.
Process:
Randomly select starting point (say, customer #23)
Then select every 50th customer: #23, #73, #123, #173, #223, etc.
Continue until you have 200 customers
Potential problem: If the customer database was organized chronologically and there's a seasonal pattern (like more sales every 50th day due to monthly promotions), you might accidentally oversample customers who buy during sales periods, skewing your results about normal purchasing behavior.
Example Scenarios where Systemic Sampling is better than Random sampling
Scenario 1: Door-to-Door Neighborhood Survey
You want to survey 200 households in a city of 10,000 homes about local services.
Random Sampling Problems:
You get random addresses across the city
Surveyors waste hours driving all over the city randomly
Expensive travel time between scattered locations
Some neighborhoods might get 20 visits, others get zero
Systematic Sampling Benefits:
Take every 50th house from a street-by-street list
Creates a natural walking/driving route through the city
Ensures geographic spread across all neighborhoods
Surveyors can work efficiently block by block
Much lower travel costs and time
Scenario 2: Employee Exit Survey Program
A large company wants to survey departing employees - they have about 500 departures annually and want to interview 100.
Random Sampling Problems:
Randomly selected departure dates create unpredictable workload
Surveys may go to 8 people one week, zero the next
Hard to randomize appropriately since you don’t know about future departures
Systematic Sampling Benefits:
Interview every 5th departing employee
Predictable, manageable workload for HR staff
Ensures coverage across all months/seasons
Easy to track and implement
Catches seasonal patterns in why people leave
Cluster Sampling
Cluster sampling divides the population into groups (clusters), randomly selects some clusters, then surveys everyone within the chosen clusters or takes a sample from each selected cluster. It's most valuable when individual sampling frames don't exist, populations are geographically scattered, or logistic costs of reaching all clusters are high. Common applications include national surveys (sampling cities then households), educational research (sampling schools then students), and market research (sampling stores then customers). The main trade-off is reduced statistical precision for significantly lower costs and easier logistics, making it essential when other sampling methods are impractical or impossible.
Pros:
Cost-Effective for scattered populations: Reduces travel and administrative costs by sampling clusters (e.g., schools, geographic areas) rather than individuals.
Logistically Feasible: Easier to manage when dealing with large, geographically dispersed populations.
Practical when no complete list exists - Don't need a sampling frame of all individuals, just of clusters
Cons:
Higher Sampling Error: Can introduce more sampling error compared to random sampling because individuals within clusters might be more similar to each other.
Complex Analysis: Statistical calculations must account for clustering effects
Requires larger sample sizes - Need more total respondents to achieve same precision as simple random sampling
Example: You want to study academic stress among 50,000 students across 200 schools in a state, but logistics of surveying random students at every school is too expensive.
Cluster sampling approach:
Define clusters - Each school is a cluster
Random selection - Randomly select 20 schools out of 200
Data collection - Survey all students in those 20 schools (or randomly sample within each school)
Why cluster sampling works here:
Cost savings - Survey only 20 schools instead of potentially 200
Logistics - Easier to coordinate with 20 schools than arrange scattered individual surveys
Efficiency - Can survey entire classes at once
Potential problems:
Students within the same school might have similar stress levels (due to school culture, academic rigor, etc.)
Selected schools might not represent the full range of school types (urban vs rural, large vs small, public vs private)
Convenience sampling
Convenience sampling selects participants based on their easy availability and accessibility to the researcher, such as surveying people in a mall, students in your class, or online volunteers. It's commonly used in exploratory research, pilot studies, market research at events, and situations with tight budgets or time constraints. The trade-off is significant bias and inability to generalize results to the broader population for extremely low cost, speed, and simplicity of data collection.
Pros:
Ease of Access: Quick and easy to implement, useful for exploratory research or pilot studies.
Low Cost: Generally inexpensive since it utilizes readily available participants.
Higher response rate: People are often willing when approached directly
Good for pilot studies - Useful for testing surveys or exploring initial ideas
Cons:
High Bias Risk: Likely to produce biased results, as it does not represent the entire population.
Limited Generalizability: Findings cannot be reliably generalized to the broader population.
Limited statistical validity: Can't calculate proper confidence intervals or significance tests and results often questioned due to methodological weaknesses.
Example: A company wants to understand how remote work affects employee productivity across their 5,000-person workforce.
Convenience sampling approach:
Send email survey link to all employees through company newsletter
Post survey link on internal company social media/Slack channels
Ask managers to share the link in team meetings
Keep survey open for 2 weeks, collect whoever responds
Why convenience sampling works here:
Easy distribution - Existing communication channels reach everyone
Cost-effective - No additional recruitment or incentive costs needed
Quick turnaround - Can gather feedback rapidly for immediate business decisions
Typical results:
Might get 800-1,200 responses (16-24% response rate)
Likely over-represents engaged, tech-savvy employees who check email regularly
May underrepresent busy departments, field workers, or less engaged staff
Limitations of this approach:
Self-selection bias - Only motivated employees respond, potentially skewing results toward those with strong opinions.
Digital divide - Misses employees who rarely check email or use company platforms.
Department bias - Some teams more likely to participate than others.
Cannot generalize - Results reflect respondents' views, not necessarily all 5,000 employees.
When this is acceptable:
Exploratory research to identify key issues
Quick pulse checks for immediate decisions
When budget/time constraints make probability sampling impossible
Gathering initial insights before designing more rigorous studies
Quota Sampling
Quota sampling selects participants to fill predetermined quotas based on key population characteristics (like age, gender, or income), but uses convenience methods to find people within each quota category. It's commonly used in market research, political polling, and media surveys when you need demographic representation but lack time or resources for probability sampling. The trade-off is potential bias within quota groups and inability to calculate sampling error for much faster, cheaper data collection with controlled demographic representation.
Pros:
Ensures representation: Ensures specific segments of the population are represented, useful when certain subgroups are of particular interest.
Faster and cheaper: Can be quicker and less expensive than random sampling or stratified sampling.
Flexible data collection and practical when sampling frames don't exist - Can adjust approach to fill remaining quotas. Don't need complete population lists
Cons:
Selection bias risk: Non-random selection within quotas can introduce bias.
Cannot calculate sampling error - No valid statistical inference about population parameters.
Limited generalizability - Results may not truly represent the broader population.
Complex implementation: Requires careful planning to set and fill quotas appropriately.
Example: Political Opinion Poll
A news organization wants to survey 1,000 voters about upcoming elections, ensuring their sample matches the voting population demographics.
Quota sampling approach:
Set quotas: 52% female/48% male, 35% ages 18-35, 40% ages 36-55, 25% ages 55+
Post survey on social media platforms and news website
Monitor responses in real-time and adjust targeting (boost posts to underrepresented groups)
Close survey when all quotas are filled
Why quota sampling works here:
Demographic control - Ensures age and gender representation matches voter registration data.
Speed - Can complete survey in days rather than weeks
Limitations:
Platform bias - Online respondents may differ from all voters in unmeasured ways.
Self-selection - Only politically engaged people likely to complete political surveys.
Missing quotas - Might struggle to find certain demographic combinations online.
Results provide a demographically balanced snapshot but can't claim statistical representativeness of all voters.
Snowball Sampling
Snowball sampling starts with initial participants who then recruit additional participants from their networks, creating a chain of referrals that grows like a rolling snowball. It's commonly used in online surveys for hard-to-reach populations, niche communities, or sensitive topics where traditional sampling methods fail. The trade-off is significant network bias and inability to generalize results for access to otherwise unreachable populations and rapid sample growth through social connections.
Pros:
Access to hard-to-reach populations: Useful for studying rare or hard-to-reach populations where members are connected.
Cost-effective and rapid sample growth: Relatively low cost and easy to implement in specific contexts. Can quickly build large samples through network effects
Identifies tight-knit communities - Effective for studying specific subcultures or professional groups
Cons:
Network bias and lack of representativeness: High potential for bias, as the sample may not represent the wider population.
Limited diversity - Tends to recruit similar people within the same social circles.
Uncontrolled growth - Difficult to predict final sample characteristics.
Dependence on initial contacts: Relies heavily on initial contacts, who may not lead to a diverse sample.
Example: Cryptocurrency Investor Behavior Study
A researcher wants to study investment patterns among cryptocurrency enthusiasts, but there's no comprehensive list of crypto investors.
Snowball sampling approach:
Start with 10 known crypto investors from Reddit communities or LinkedIn
Each completes survey and shares unique link with 3-5 other crypto investors they know
New participants repeat the process, sharing with their crypto networks
Track referral chains to monitor sample growth
Why snowball sampling works here:
Hard-to-identify population - No registry of cryptocurrency investors exists
Community trust - Crypto investors skeptical of outsiders but trust peer recommendations
Network effects - Crypto communities are highly interconnected online
Rapid growth - Can reach hundreds of participants quickly through social sharing
Limitations:
Echo chamber effect - May only capture certain crypto communities (Reddit users, not institutional investors)
Geographic clustering - Networks often concentrated in specific regions or platforms
Demographic bias - Likely overrepresents young, tech-savvy, male investors
Cannot represent all crypto investors - Results only reflect the specific networks reached
This method provides valuable insights into crypto investor behavior within certain communities but cannot claim to represent all cryptocurrency investors globally.
Purposive/Judgmental Sampling
Purposive/Judgmental Sampling deliberately selects participants based on researcher judgment about who can provide the most valuable information for the study's specific objectives. It's commonly used in expert interviews, specialized professional surveys, and exploratory research where deep knowledge matters more than statistical representation. The trade-off is complete reliance on researcher judgment and inability to generalize for access to highly relevant, knowledgeable participants who can provide rich, targeted insights.
Pros:
Highly relevant participants - Targets people with specific expertise or characteristics
Rich, detailed data - Knowledgeable participants provide deeper insights
Cost and time efficient - Focuses resources on most valuable respondents and no need for complex sampling procedures
Flexible selection - Can adapt criteria as research evolves
Good for exploratory studies - Ideal when you need expert perspectives to understand complex topics
Cons:
Researcher bias and subjective selection- Selection depends entirely on researcher judgment and different researchers might choose different participants
Cannot generalize and limited statistical validitity- Results only reflect selected participants' views and no probability-based foundation for inference
Example: Telemedicine Implementation Study
A healthcare researcher wants to understand challenges in implementing telemedicine systems from the perspective of medical professionals.
Purposive sampling approach:
Identify doctors who have implemented telemedicine in the past 2 years through medical association databases
Target specific specialties (primary care, psychiatry, cardiology) known for telemedicine adoption
Recruit through LinkedIn, medical forums, and professional networks
Select participants based on experience level, practice type, and geographic diversity
Why purposive sampling works:
Expert knowledge: Only experienced practitioners can provide meaningful insights
Targeted expertise: Focuses on those who've actually implemented systems, not theorists
Practical insights: Captures real-world implementation challenges and solutions
Multi-stage Sampling
Multi-stage Sampling combines multiple sampling methods in sequential stages, typically moving from larger to smaller units (e.g., states → counties → neighborhoods → households). It's essential for large-scale national surveys, government studies, and research covering vast geographic areas where single-stage sampling would be impractical. The trade-off is increased complexity and potential for cumulative sampling errors for feasibility in studying large, dispersed populations cost-effectively.
Pros:
Practical and cost-effective for large populations: Makes national or regional studies feasible and reduces administrative costs compared to simple random sampling
Maintains representativeness: Can achieve population representation through careful stage design
Flexible design and more control: Can adapt sampling methods at each stage based on available resources and research goals, more control to ensure coverage across different sub groups
Cons:
Complex design: Requires careful planning and statistical expertise
Cumulative sampling error: Errors from each stage compound the final precision and it’s usually less precise than simple random sampling of same size
Expensive analysis: Requires more sophisticated statistical analysis and methods
Multiple sampling frames: Need complete lists at each stage
Coordination challenges: Managing data collection across multiple stages and locations
Example: National Student Mental Health Study
Researchers want to study college student mental health across the entire United States.
Multi-stage sampling approach:
Stage 1: Randomly select 8 states from 4 geographic regions (2 per region)
Stage 2: Randomly select 5 universities from each state (40 total universities)
Stage 3: Randomly select 3 academic departments from each university
Stage 4: Online survey sent to all students in selected departments
Why multi-stage works:
National scope - Covers entire US without surveying every university
Manageable logistics - Negotiate with 40 universities instead of thousands
Regional representation - Ensures geographic diversity in final sample
Cost control - Concentrates effort while maintaining broad coverage
Panel Sampling
Panel Sampling surveys the same group of participants repeatedly over time, tracking changes in attitudes, behaviors, or conditions across multiple time points. It's crucial for longitudinal research, political tracking polls, consumer behavior studies, and any research examining change over time. The trade-off is panel attrition and potential conditioning effects for powerful insights into individual and group changes over time.
Pros:
Tracks individual changes: Shows how same people change over time, not just group averages
High statistical power: Each person serves as their own control, reducing variability
Reveals causation patterns: Can better establish cause-and-effect relationships
Cost-efficient over time: Sometimes cheaper than recruiting new samples repeatedly
Rich longitudinal data: Captures trends and patterns invisible in cross-sectional studies
Participant familiarity: Respondents become comfortable with process, improving response quality
Cons:
Panel attrition: Participants drop out over time, potentially biasing results
Conditioning effects: Repeated surveying may change how participants think or behave
Initial recruitment burden: Requires significant upfront effort to build committed panel
Maintenance costs: Ongoing communication and incentives needed to retain participants
Selection bias: People willing to participate long-term may differ from general population
Aging and characteristic effects: Panel demographics change over time as participants age, they could also lose the original criteria that they were originally recruited for (e.g. new users of a platform may meet criteria for new users over time)
Example: COVID-19 Impact on Remote Work
A research firm wants to track how employee attitudes toward remote work change throughout the pandemic and recovery.
Panel sampling approach:
Recruit 2,000 office workers in March 2020
Survey same participants every 3 months for 2 years
Track changes in work preferences, productivity, job satisfaction
Use online platform to maintain participant engagement and send reminders
Why panel sampling works:
Individual trajectories - Shows how each person's attitudes evolve, not just group trends
Policy timing - Can correlate attitude changes with specific events (lockdowns, return-to-office mandates)
Personal factors - Identifies which individuals adapt better to remote work over time
Volunteer/Self-selected Sampling
Volunteer/Self-selected Sampling allows participants to choose whether to join the study, typically through advertisements, open invitations, or online platforms where people opt-in voluntarily. It's common in psychology research, online market research, and studies requiring high participant motivation or sensitive topic disclosure. The trade-off is severe self-selection bias and inability to generalize for easy recruitment of highly motivated participants willing to share personal information.
Pros:
High motivation and easier recruitment: Participants genuinely want to contribute, leading to better response quality. No complex selection processes or tracking down specific individuals
Cost-effective and large sample potential: Minimal recruitment costs, participants come to you and can quickly gather many participants through online platforms
Good for sensitive topics: People self-select based on comfort discussing personal issues
Cons:
Severe selection bias and limited generalizability: Only certain types of people volunteer for research. Results only apply to people willing to participate
Demographic skewing: Tends to oversample educated, affluent, younger participants
Topic bias: People with strong opinions more likely to participate
Example: Video Gaming Addiction Study
Psychologists want to study video game usage patterns and their psychological effects.
Volunteer sampling approach:
Post recruitment ads on Facebook, Instagram, Reddit, Gaming forums
Create study website where interested people can sign up
Use social media influencers to share study information
Collect 5,000 volunteers over 2 months
Why volunteer sampling works:
Sensitive topic: People need to feel comfortable discussing potentially problematic behaviors
Self-awareness required: Need participants who recognize their video gaming habits
High engagement: Volunteers more likely to complete lengthy surveys about personal habits
Limitations:
Self-selection bias: May oversample people concerned about their social media use
Platform bias: Different social media platforms attract different demographics
Cannot represent general population: Only reflects people willing to examine their digital habits
Matched Sampling
Matched Sampling deliberately selects participants to create comparable groups that are similar on key characteristics, often used to compare outcomes between different conditions while controlling for confounding variables. It's essential in comparative studies, program evaluation, and quasi-experimental research where random assignment isn't possible. The trade-off is complex matching procedures and limited generalizability for improved internal validity and ability to make causal inferences.
Pros:
Controls for confounding: Reduces bias by matching on key characteristics
Improves causal inference: Better able to attribute differences to the variable of interest. Each matched pair provides controlled comparison
Reduces sample size needs: More statistical power than unmatched designs
Good for evaluation studies: Useful when randomization isn't ethical or practical
Clear comparisons: Makes differences between groups more interpretable
Cons:
Complex matching process: Requires detailed information about potential confounders. May not find good matches for all participants
Limited generalizability and Selection bias: Results only apply to the specific matched population. Matching criteria may introduce new biases
Unknown confounders: Can only match on measured variables
Reduced sample size: Unmatched participants must be excluded
Example: Online Learning Effectiveness Study
Educational researchers want to compare student outcomes between online and in-person learning during COVID-19.
Matched sampling approach:
Survey students from universities that offered both online and in-person options
Match online and in-person students on: GPA, major, year in school, socioeconomic status
Create pairs where each online student is matched with similar in-person student
Compare learning outcomes, satisfaction, and engagement between matched pairs
Why matched sampling works:
Controls for selection effects: Online vs in-person choice might relate to student characteristics
Improves validity: Differences more likely due to learning mode, not student differences
Policy relevance: Provides clearer evidence for educational decision-making
Practical matching:
Use student records to identify potential matches
Create matching algorithm based on key academic and demographic variables
Survey both members of each matched pair using identical instruments
This approach provides stronger evidence about online learning effectiveness than simply comparing all online vs all in-person students without considering their differences.
Final thoughts
Sampling may sound dry, but it’s the hidden engine that powers trustworthy research. Each method comes with trade-offs—between cost, precision, bias, and feasibility. The key is to match your method to your research goals and constraints.
Here is a table with quick recap of sampling methods:
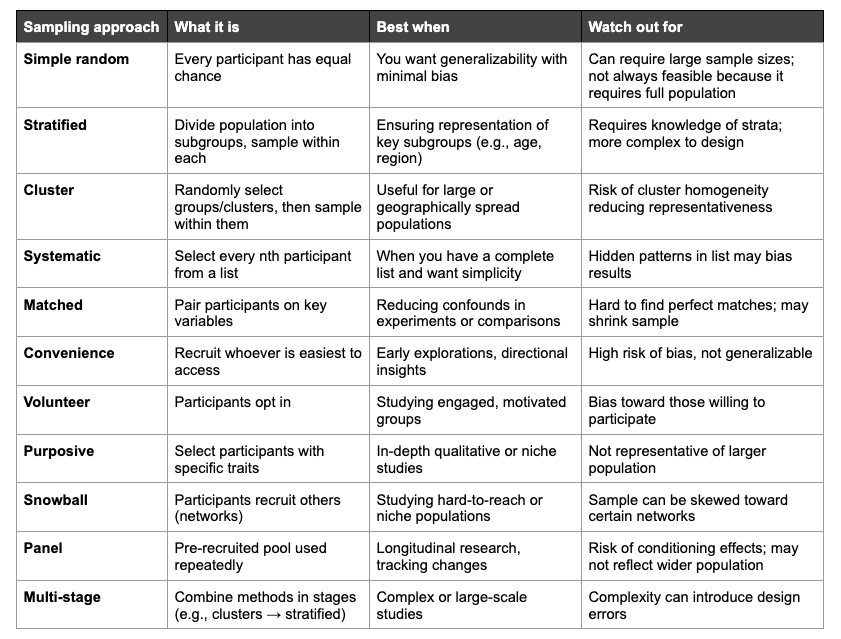
In future posts, I’ll dive into other aspects of survey research or quantitative analysis techniques. If you have a specific topic in mind that you’d like me to expand into, let me know in comments.
Loved reading this. A brilliant set of sampling methods.